🏆 MEJORES CASINOS ONLINE EN ESPAÑA🏆














CÓMO ELEGIR LOS MEJORES CASINOS ONLINE
Existen muchos criterios que necesitas seguir para elegir mejores casinos online España para jugar online. A continuación, mencionaremos los más importantes.
✅ COMPRUEBE LA LICENCIA
Los casinos online España que operan legalmente tienen permiso expedido por la DGOJ. De hecho, deben exhibir en su plataforma la licencia general o singular. Igualmente, si el operador posee una licencia otorgada por una autoridad como la Malta Gaming Authority o Curazao Gaming es un sitio fiable.
✅ SELECCIÓN DE JUEGOS
El portafolio debe ser innovador, amplio, variado, optimizado para móvil y con versiones demo. Por tal motivo, tiene que estar conformado por tragaperras, blackjack, póker, ruleta, bingo, keno, dados, baccarat, mesas en vivo, etc. O pruebe su suerte en una lotería como La Quiniela.
Además, es fundamental que los juegos sean diseñados por compañías desarrolladoras reputadas con licencia. Tal es el caso de Microgaming, Evolution Gaming, Playtech, Vivo Gaming, Pragmatic Play, NetEnt, entre otras.
✅ BONOS
Un casino español online legal fideliza a sus clientes mediante bonificaciones. Vale destacar que, el Real Decreto 958/2020 establece que los operadores solo podrán otorgar ofertas promocionales a sus clientes 30 días después del registro. Conviene saber que, antes de aceptar una recompensa leas los T&C.
✅ OPCIONES BANCARIAS
Al jugar online en mejores casino online España debes tener garantizado varios métodos para depositar y retirar con seguridad; como tarjetas bancarias, billeteras digitales, transferencias bancarias, criptomonedas, tarjetas débito y prepago. Además, que te permitan efectuar las operaciones con la mayor rapidez posible.
✅ ATENCIÓN AL CLIENTE
Un casino será ideal para jugar si dispone de un soporte al usuario en español que trabaje 24/7. También, es preciso que facilite varios canales para la comunicación como chat en vivo, línea telefónica, email y formulario online.
✅ POSIBILIDAD DE JUGAR DESDE EL MÓVIL
Mejor casino online en español tiene que ser responsiva. La idea es que los usuarios puedan jugar cómodamente desde su tableta o teléfono inteligente. Adicionalmente, es una gran ventaja que el operador ofrezca una aplicación móvil nativa descargable; la cual sea compatible con sistemas operativos iOS y Android.
✅ CLUB VIP
Los programas para clientes fieles son elementos importantes en mejor casino online España. Estos recompensan a los clientes consecuentes con muchos beneficios; como bonos, regalos especiales, invitaciones a eventos, sorteos, viajes, asistencia personalizada para retiros rápidos, por nombrar algunos.
✅ COMENTARIOS
Si revisas los casinos online España lista y observas evaluaciones deficientes y una gran cantidad de comentarios negativos. Evita jugar en estos sitios, porque no prestan servicios eficientes, son ilegales, no cumplen con la normativa, entre otras.
✅ TÉRMINOS Y CONDICIONES
Todo casino en línea en español debe publicar en español, bien redactados y estructurados los términos y condiciones. Estos términos deben hacer referencia a las bonificaciones concedidas, políticas de privacidad y tratamiento de las cookies. Asimismo, otros aspectos como registro de la cuenta, operaciones bancarias, reglas de juegos, etc.
LOS MEJORES CASINO ONLINE DE ESPAÑA EN 2024
| Rank | Casinos Online | Depósito Mínimo |
| 1 | GratoGana | 10 |
| 2 | Platin | 10 |
| 3 | Luckia | 5 |
| 4 | 777 | 10 |
| 5 | Party Poker | 5 |
| 6 | Genesis | 10 |
| 7 | Casumo | 10 |
| 8 | 888 | 10 |
| 9 | LeoVegas | 10 |
| 10 | Mr. Green | 10 |
| 11 | Betsson | 10 |
| 12 | Betway | 10 |
| 13 | Codere | 10 |
| 14 | PlayUZU | 10 |
| 15 | Betfred | 7 |
CALIFICACIÓN DE LOS MEJORES CASINOS ONLINE EN ESPAÑA
En nuestra revisión, hicimos una revisión detallada de los casinos confiables en España. Compruebe cómo calificamos los casinos en línea.
MEJORES CASINOS EN ESPAÑA
Preparamos la calificación del mejor casino en línea en España para que nuestros usuarios puedan obtener solo una experiencia de juego exclusiva.
| Mejores casinos en España | Calificación |
| Betsson | 100 |
| Leo Vegas | 95 |
| 888 | 90 |
| Luckia | 85 |
| Pastón | 80 |
| Marca Apuestas | 75 |
| Bethard | 70 |
| Betway | 65 |
| StarVegas | 60 |
| Betfair | 55 |
MEJOR CASINO NUEVO
Los nuevos casinos online pueden ofrecerle una experiencia emocionante y nuevas funciones.
| Mejor casino nuevo | Calificación |
| Wanabet | 100 |
| Win | 95 |
| Yobingo | 90 |
| Mansion | 85 |
| Casumo | 80 |
| Genésis | 75 |
| 777 | 70 |
| Bwin | 65 |
| Party Poker | 60 |
| Todoslot | 55 |
MEJORES CASINOS SEGUROS Y FIABLES
La identificación de la seguridad es nuestra prioridad, por eso ofrecemos solo casinos legales.
| Mejores casinos seguros y fiables | Calificación |
| Gran Madrid | 100 |
| Barcelona | 95 |
| LeoVegas | 90 |
| Paf | 85 |
| Lukia | 80 |
| Mbet | 75 |
| Maratonbet | 70 |
| Win | 65 |
| Mansion | 60 |
| Casumo | 55 |
LOS MEJORES CASINOS CON BONOS
Sabemos que los bonos son cruciales para nuestros lectores. Pero debe recordar que los bonos en los casinos online España están disponibles solo después de 30 días después del registro. Aun así, creamos una lista de casino con bonos para ti.
| Mejores casinos con bonos | Calificación |
| 1×2 bet | 100 |
| William Hill | 95 |
| Play Uzu | 90 |
| Bacanaplay | 85 |
| Sportium | 80 |
| MrGreen | 75 |
| Jokerbert | 70 |
| PokeStar | 65 |
| Suertia | 60 |
| Mansion | 55 |

😋 CÓMO ABRIR UNA CUENTA EN UN MEJOR CASINO EN LÍNEA 😋
Puedes registrarte en mejores casinos siguiendo los pasos que se indican a continuación.
- Ve a la página principal del mejor casino online españa
- Cliquea la pestaña «Registrarse»
- Completa un formulario para el registro, ingresando tus datos de contacto y personales
- Crea un nombre y contraseña como usuario.
- Lee y acepta los términos y condiciones del casino España
- Envía el formulario
- Verifica en tu correo electrónico si tienes un enlace de verificación para iniciar sesión desde allí.
- En pocos segundos podrás acceder al sitio
🎰 CÓMO EMPEZAR A JUGAR EN EL MEJOR CASINO ONLINE 🎰
- ELEGIR UN CASINO EN LÍNEA – El primer paso para jugar en casinos online español, es escoger un sitio seguro, legal, confiable y con buena reputación. Las páginas comparativas expertas y objetivas como Juegosiesta pueden recomendártelos. Además, es posible consultar operadores legales en las páginas web de Juego Seguro y Jugar Bien.
- REVISAR LOS CASINOS ONLINE ESPAÑA ELEGIDO – Tienes que hacer tu tarea investigativa al seleccionar los casinos en línea. Así que, comienza a revisar la plataforma para verificar que tienen licencia. Igualmente, evalúa si la librería exhibe los juegos que buscas. Asimismo, comprueba si dispone de ofertas promocionales ventajosas para ti. También, toma un tiempo para que revises si te convienen los T&C del operador.
- REGISTRO – Para jugar en un casinos online España tienes que cumplir con un proceso para el registro. Esto se hace ingresando a la plataforma del operador, busca el botón “Registrarse” y haz clic en el mismo. Luego completa correctamente el formulario con los datos que te solicitan. Al terminar con el formulario finaliza el registro y espera el email para confirmar la cuenta.
- HACER UN DEPÓSITO – Después del registro en los casinos online en español y antes de jugar tienes que recargar tu cuenta. Así que, debes hacer un depósito escogiendo el método más conveniente para ti. Recuerda que el medio elegido para tu primer ingreso debe ser el mismo a la hora de retirar las ganancias.
- EMPEZAR A JUGAR – Una vez que hayas realizado tu primer depósito tendrás dinero en tu cuenta para comenzar a jugar en paginas de casino en linea. Sin embargo, si efectuaste un ingreso mínimo solo dispondrás de fondos para disfrutar los juegos con límites para apostar bajos. Por otra parte, si aciertas en tus apuestas en el menú “Cuenta”, podrás consultar tu saldo.Así, sabrás con cuánto dinero cuentas para jugar en casinos online España.






👛 CONSEJOS PARA GANAR EN LOS MEJORES CASINOS ONLINE 👛
Prepárate para conocer los consejos que te ayudarán a ganar en casino online españoles.
✨ COMPRUEBE PRIMERO EL PAGINA DE MEJOR CASINO ONLINE ESPAÑA
Evita riesgos en un mejor casino en línea. Por esta razón, antes de registrarte evalúa ciertos elementos; como la licencia del operador, además los términos deben explicarte claramente las reglas del sitio. También, revisa si la plataforma tiene juegos que te gusten, si tiene métodos seguros para pagar y si otorga bonos.
✨ ELIJA JUEGOS CON UN RTP ALTO
Es un porcentaje teórico de lo que devolverá un juego luego de un lapso de tiempo. Entonces, es prudente elegir títulos con RTP elevados en casinos online. La media en la industria es 96%, por tanto, si el porcentaje es mayor te conviene, porque, por cada 100 € apostados el juego retorna 96 €.
✨ APRENDA LAS REGLAS
Tus posibilidades para ganar aumentarán si conoces bien las reglas en los juegos elegidos en la página en casino online España. Por ello, es fundamental que si eres novato no te arriesgues tu dinero. Primero conoce bien la dinámica del título y cuando estés listo apuesta con límites bajos.
✨ COMPRUEBE ALGUNAS ESTRATEGIAS GANADORAS
Para tener éxito en un casino en línea España, necesitarás implementar ciertas estrategias, las cuales puedes conseguir en nuestros artículos o blogs especializados.
Además, podrías consultar éxitos literarios sobre casinos; como “Gánale a la Banca” de Edward Thorp o Vencer en la Ruleta escrito por Mario Teresano.
✨ PRUEBE EL JUEGO EN LA VERSIÓN DEMO PRIMERO
Si eres un jugador novato en un mejor casino online España, evita hacer apuestas con dinero real apresuradamente. Primero afina tu estrategia y conoce las reglas jugando la versión demo del juego escogido, cuando estés seguro apuesta.
✨ JUEGUE CON BONOS
Los bonos te concederán un impulso extra para apostar, así no pondrás tu dinero en riesgo. Además, las bonificaciones te permiten conocer la plataforma del casino online españa. Igualmente, te permitirán interactuar con los juegos que te llamen la atención.
✨ JUEGUE EN CASINOS ONLINE EN ESPAÑOL CON REQUISITOS DE APUESTA BAJOS
Muchos bonos de casino online representan ofertas difíciles de resistir. Sin embargo, antes de aceptarlos fíjate en los requisitos para apostar. Debido a que si el rollover es muy elevado será complicado liberar el bono. Imagina que recibes un bono por 50 € y el rollover es 30x. Tendrías que apostar 30 veces el bono, entonces tendrías que invertir 1500 € para conseguir solo 50 €.
✨ ESTABLEZCA LÍMITES SI NO TIENE EXPERIENCIA
Los casinos españoles online legales deben propiciar el juego responsable. Así que en sus plataformas tienen opciones para establecer límites en los depósitos y el tiempo jugando. Si eres novato, estas acciones te ayudarán a controlar tu presupuesto y evitar los riesgos de la ludopatía.
✨ PRUEBE LOS JUEGOS CON BOTE
Sin lugar a dudas, si tienes suerte los juegos de casinos online con bote podrían cambiar tu vida. Estos reparten sumas de dinero astronómicas que pueden convertirte en millonario. Generalmente las tragaperras son los juegos que habitualmente incluyen jackpot, también el póker y la ruleta.
✨ LEE LOS COMENTARIOS DE OTROS JUGADORES SOBRE EL JUEGO
Gracias al desarrollo del Internet podrás evaluar los casas de slots online, tomando en cuenta los comentarios emitidos por otros jugadores. Existen sitios en la web que los recopilan, por tanto, si un casino tiene demasiadas opiniones negativas es mejor ignorarlo.
✨ RECUERDE QUE UN DEPÓSITO MÍNIMO NO LE PROPORCIONARÁ MUCHO DINERO
Un depósito mínimo de 10 € te ayudará a iniciarte como cliente en un online casino. De hecho, podrás probar juegos con límites para apostar reducidos. No obstante, si deseas obtener ganancias mayores tienes que ingresar montos más altos y arriesgarte probando tu suerte.

🇪🇸 REGULACIÓN DE MEJORES CASINO ONLINE EN ESPAÑA 🇪🇸
En 2011 fue aprobada la ley de regulación del juego. Según esta legislación todo online casino Espana que quisiera operar debería tener licencia otorgada por la Dirección General de Ordenación del Juego.
La DGOJ otorga licencias generales y singulares a los operadores. Así que, para obtenerlas deben cumplir requisitos legales, económicos y técnicos. También, adicional a la ley que regula el juego existen otras normas en vigor.
Tanto la DGOJ y el ministerio de Haciendo ejercen todo el control, así que tienen la potestad para sancionar y supervisar a la Lotería, Casas de Apuestas y Casinos España Online. Asegurando al jugador métodos de pagos fiables, juego transparente, protección de privacidad.
El jugador estará bajo la normativa española con lo cual también debe cumplirla, esto incluye pagar impuestos y declarar la renta solo si se obtiene ganancias del casino que superan los 1000€ y no haya otros ingresos paralelos. En todo caso, si tienes dinero de otra fuente, aunque fuera solo 1€ debes reflejarlo en la declaración de la renta.
Cabe destacar que, actualmente hay más de 70 operadores con licencia. Sin embargo, los españoles deciden si juegan con ellos o con casinos con licencias otorgadas por otras autoridades internacionales y será legal.
Lea más sobre la regulación de casinos en España en nuestro blog.
LA SITUACIÓN ACTUAL DE LOS MEJORES CASINOS ONLINE ESPAÑA
Hace unos meses fue publicado el Real Decreto 958/2020. Donde se regula la publicidad relacionada con el juego en línea para impulsar el juego responsable. De hecho, las casas con licencia en España han sido obligadas a limitar la publicidad de sus ofertas promocionales.
Además, los clientes nuevos en estas plataformas no podrán recibir bonos de bienvenida al crear su cuenta. Esto se debe a que, los casinos de España online solo tienen permitido conceder estas ofertas personalizadas luego de 30 días del registro del usuario.
¿QUÉ NECESITAS PARA JUGAR EN UN CASINO EN LINEA EN ESPAÑOL?
- Ser mayor de 18 años.
- Enviar al casino online español de manera digitalizada el DNI o NIE, factura con domicilio y extractos bancarios.
- Verificación de cuenta.
- Revisar previamente los términos & condiciones.
- Juega con responsabilidad en online casino espana.
☀️ SEGURIDAD EN PAGINAS CASINO ONLINE ☀️
Un online casino España cumple con las normativas del juego seguro cuando presta servicios desde casino online con dominio (.es). También, se adaptan a las resoluciones sobre homologación de sistemas técnicos. Donde los sistemas de información y software del juego son auditados por entidades independientes.
Además, publican reglas transparentes y ofrecen un soporte al usuario eficiente. Igualmente, las operaciones monetarias están protegidas, cumplen con la ley orgánica de protección de datos e impulsan políticas para fomentar el juego responsable en mejores casinos online.
¿QUÉ CONDICIONES SIGUEN LOS CASINOS ONLINE ESPAÑOLES MÁS CONFIABLES?
- En sus términos fijar reglas claras y transparentes.
- Sitio de un casino online en España es seguro.
- El sistema de información y software de juego es auditado por compañías independientes certificadoras.
- Protege los datos de sus usuarios.
- Está afiliado al Servicio Phishing Alert de la DGOJ.
- Impulsa el juego responsable con medidas de auto prohibición y evita registro de menores de edad.
- Las transacciones monetarias están blindadas.
- Sus clientes están amparados por las leyes.
🔥 MEJORES CASINOS ONLINE RECOMENDADOS 2024 🔥
Existen muchos casinos online España. Sin embargo, entre los favoritos se encuentran los siguientes:
✅ 888
El consorcio 888 Holdings PLC comenzó sus operaciones online en 1997 y actualmente tiene más de 25 millones de clientes. Vale destacar que, los servicios de procesamiento de transacciones de sus entretenimientos son manejados por Virtual Global Digital Services Limited.
LICENCIA
Dirección General de Ordenación del Juego.
JUEGOS DISPONIBLES
Se distingue del resto de los casinos online España por su portafolio de juego; el cual está conformado por tragaperras, póker, blackjack, ruleta, bacará, keno, craps y tarjetas de rasca y gana.
APLICACIÓN
Si, disponible para iOS y Android.
EXPERIENCIA DE CASINO EN VIVO
Su repertorio de live casino online está conformado por mesas de blackjack, bacará, póker y ruleta. También, tienen juegos populares como Crazy Time, Monopoly Live, Cash or Crash, Mega Wheel y muchos más.
DEPÓSITO MÍNIMO
El monto mínimo es 10 €.
VENTAJAS:
- Ha sido galardonado varias veces.
- Gran oferta de juegos.
- Programa VIP.
DESVENTAJAS:
- Sin línea para atención telefónica.
✅ GRATOGANA
Gratogana llega como casino online España para ofrecer los juegos online más populares y nuevos lanzamientos con la mejor tecnología avanzada de proveedores líderes de la industria eGaming. Este sitio es operado por la compañía Playes PLC con registro C89276. Toda una compañía de juegos de azar que promete calidad, seguridad y protección a sus jugadores.
LICENCIA
El casino online España Gratogana tiene la licencia DGOJ.
JUEGOS DISPONIBLES
Como todo casino online España, Gratogana está formada por desarrolladores digitales como iSoftbet, Relax Gaming, Anakatech e IGT que abastecen la pagina con los juegos, tales como: tragaperras, clásicas, tarjetas rasca y gana, ruletas y blackjack.
APP
No tiene app. Tiene tecnología responsive como otros casinos online España.
EXPERIENCIA EN EL CASINOS EN VIVO
Gratogana es de los pocos casinos online España que no ofrece casino con crupier. Sin embargo, los juegos de mesa que incluyen la ruleta y el blackjack son en tercera dimensión.
MÍNIMO DE DEPÓSITO
Gratogana te permite hacer un depósito mínimo 10€.
PROS Y CONTRAS
Conoce las ventajas y desventajas de
Pros
- Variedad de tragaperras y tarjetas rasca y gana.
- Tiene licencia española.
- Atención al cliente las 24/7.
Contras
- Sin aplicación.
✅ 777
777 es operado por la compañía S.A Española Digital Distribution Management Ibérica. 777 online del 2016 es uno de los mejores casinos online a los que puede acudir cualquier jugador español. Ofrece diversos métodos bancarios, promociones, atención al cliente y una gran cartera con los juegos más populares del mercado.
LICENCIA
Este 777 online cuenta con la licencia española, DGOJ.
JUEGOS DISPONIBLES
777 ofrece una amplia cartera con todos los títulos que incluye las tragaperras para todos los gustos, vídeo bingo, vídeo póker y juegos de mesa como la ruleta y el blackjack.
APLICACIÓN
777 no tiene aplicación, pero como otros casinos online España, su página web es responsive.
EXPERIENCIA EN EL CASINOS EN VIVO
777 como buen casino online España tiene juegos en vivo con crupier. Casino online permite a los jugadores jugar a la ruleta en tiempo real e interactuar con el crupier a través del chat en vivo.
MÍNIMO DEPÓSITO
El casino online 777 pone como mínimo para depositar 10€.
PROS Y CONTRAS
Regístrate en 777 conociendo las ventajas y desventajas de pagina casino online.
Pros
- Múltiples tragaperras.
- Posee la licencia DGOJ.
- Optimizado para cualquier dispositivo inteligente.
Contras
- No tiene baccarat.
✅ CASUMO
Casumo es un Casino online España es operado por Casumo Spain PLC qucom. Lleva en la industria una década, pero no es hasta el 2019 que consigue ser uno de los casinos online España con licencia. Desde entonces, los españoles pueden hacer sus apuesta de un juego seguro y transparente.
LICENCIA
Casumo es un casino online España con licencia DGOJ.
JUEGOS DISPONIBLES
Casumo casino online ofrece una biblioteca formada por los mejores desarrolladores digitales como PlaynGo, Netent, Evolution Gaming, Microgaming que solo encuentras en los mejores casino online España. Dentro del repertorio encuentras tragaperras clásicas y en vídeo, blackjack y ruletas.
APLICACIÓN
No tiene app. Es responsive como otros casinos online España
EXPERIENCIA EN VIVO
Casumo tiene casino live con crupier donde los jugadores pueden jugar a las diferentes ruletas y apostar con dinero real, además, interactuar con el crupier por el live chat.
MÍNIMO DEPÓSITO
Para apostar en Casumo debes hacer el depósito mínimo de 10€
PROS Y CONTRAS
Сonociendo las ventajas y desventajas de este
Pros
- Tiene +400 slots online españa.
- Tiene juegos con crupier.
- Atención al cliente las 24/7.
Contras
- Sin app.
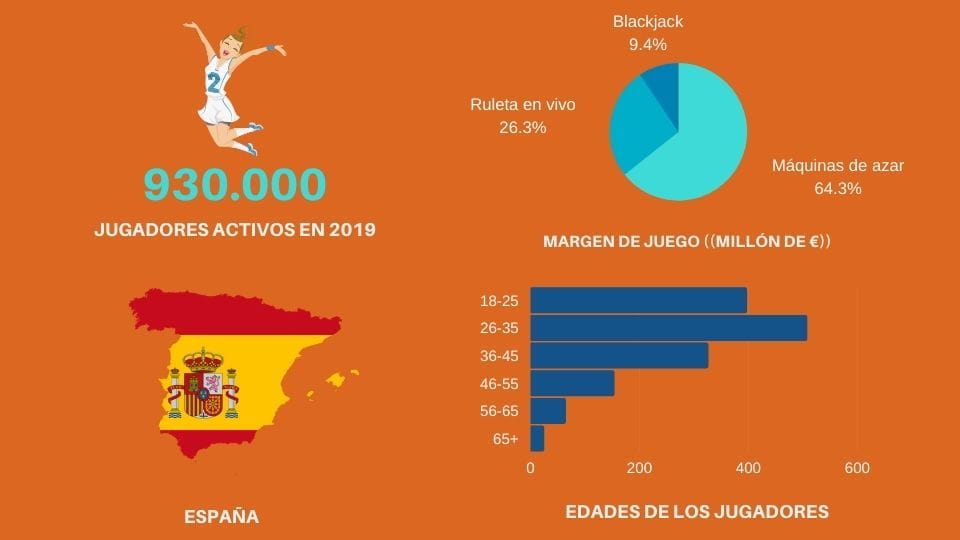
🇪🇸 EL JUEGO EN MEJORES CASINOS ONLINE ESPAÑA – ESTADÍSTICAS 🇪🇸
En España son muchos los jugadores que eligen la diversión a través del casino online y cada vez más, prefieren hacerlo online. Según las estadísticas en 2019, constaron al menos 930.000 jugadores activos. Además, más del 80% de los jugadores tienen edades que oscilan entre los 18 a 45 años.
Asimismo, el juego en casinos online aumentó más del 8% alcanzando hasta los 18.000€ millones. Los juegos al azar que más beneficio han dejado son slot online españa con un margen del juego de 13,29€ y la ruleta 5,43€ millones.
Aproximadamente una media de 38€ por depósito, y 45 millones en depósitos para fondos en el años 2018 realizaron los jugadores. Paralelamente, al menos 6,8 millones de retiradas de depósito, con una media del importe sobre 159€.

😎 CÓMO HACER UN DEPÓSITO ONLINE MEJORES CASINOS EN ESPAÑA 😎
Los pasos para depositar en online casino España, son muy sencillos e intuitivo, solo tienes que seguir los siguientes pasos:
- Dirígete a la sección “Depositar” y cliquea para revelar los múltiples métodos para pagar.
- Selecciona el método bancario: tarjeta bancaria, monedero electrónico o transferencias bancarias
- Ingresa la cantidad que deseas depositar.
- Completa el formulario para el pago, como el nombre y número del titular de la tarjeta o cuenta bancaria o correo electrónico y contraseña en los monederos.
- Acepta el pago
- Revisa el código verificación de identidad en tu móvil para finalizar el pago
- En breves segundos tendrás el dinero en tu cuenta del mejor casino online españa
MÉTODOS DE PAGO Y RETIRO EN MEJORES CASINO ONLINE ESPAÑA
🔶 VISA Y MASTERCARD – Son tarjetas de crédito con muchos usuarios. El mínimo de depósito oscila entre 5€ a 20€, dependiendo del casino online y tiene un tiempo de espera que puede tardar de 3 a 5 días. Sin ninguna comisión.
🔶 MAESTRO – Esta tarjeta débito opera similar que las anteriores y no tiene ninguna comisión. El tiempo de transacción puede ser al menos 3 a 5 días. Con un mínimo de depósito que oscila entre 5€ a 20€.
🔶 PAYPAL – Esta billetera virtual permite hacer los depósitos transferencias inmediatas.Tiene una comisión del 2,9%.
🔶 NETELLER – Este monedero electrónico tiene un comisión del 2,50% y el tiempo de transacción es inmediato.
🔶 SKRILL – Este monedero electrónico funcionan rápido agilizando el movimiento de fondos muy efectivamente. Con una comisión estándar es 1,45% y tiempo de transferencia es inmediato.
🔶 TRUSTLY – Es una cuenta que permite hacer pagos online desde tu cuenta bancaria. No tiene comisión y los depósitos mínimos suelen ser 10€. El tiempo de transacción es inmediato.
🔶 ASTROPAY – Es una tarjeta virtual prepago que no tiene ningún tipo de comisión.
OPCIONES DE PAGO POPULARES EN LOS MEJORES CASINOS ESPAÑOLES
| Métodos de pago | Tiempo de depósito | Tiempo de retiro |
| Paypal | Instantáneo | 24 horas a 2 días |
| Neteller | Instantáneo | 24 horas a 2 días |
| Skrill | Instantáneo | 24 horas a 2 días |
| Bizum | Instantáneo | No disponible |
| Transferencia Bancaria | Instantáneo | 3 a 7 días laborables |
| Bitcoin | Instantáneo | 0 a 1 hora |
| Visa | Instantáneo | 2 a 4 días laborables |
| Mastercard | Instantáneo | 2 a 4 días laborables |
| Maestro | Instantáneo | 2 a 4 días laborables |
| Paysafecard | Instantáneo | No disponible |
| Sofort | Instantáneo | 24 horas a 2 días |
| Trustly | Instantáneo | 24 horas a 2 días |
| Much Better | Instantáneo | 24 horas a 2 días |
💰 CÓMO RETIRAR SUS GANANCIAS EN MEJORES CASINOS ONLINE 💰
- Si es tu primer retiro verifica previamente tu identidad.
- Inicia sesión como usuario del casinos online.
- Ingresa al menú “Cuenta”.
- Busca el botón “Caja o Banco”.
- Pulsa clic en el botón “Retirar”.
- Coloca el monto que deseas.
- Elige el método de pago que usaste al depositar.
- Confirma la operación.
🔵 ASEGÚRATE DE QUE HAS COMPLETADO TODOS LOS REQUISITOS PARA APOSTAR EN MEJORES CASINOS ESPAÑA ONLINE
Si obtuviste una bonificación en un mejor casino online espana y deseas liberarla obligatoriamente tendrás que cumplir con los requisitos para apostar del operador. Cualquier intento de retiro sin haber cumplido el rollover ocasionará que tu bono y ganancias sean invalidados.
🔵 LÍMITES DE RETIRADA
Esto dependerá de mejores casinos online en español donde te registres y el método para pagar que emplees para retirar. Es preciso señalar que, en la mayoría establecen una cuantía mínima que no supera los 10 €. Asimismo, el límite máximo para retiradas varía desde 2000 € hasta 75.000 €.
🔵 LÍMITES DE TIEMPO
Al efectuar un retiro generalmente el mejor casino online español tardan 24 horas para tramitarlo. Luego dependiendo del método elegido tienes que esperar el lapso que demoran. Por ejemplo, las tarjetas bancarias tardan entre 1 y 5 días, las transferencias bancarias entre 2 y10 días y, los monederos digitales 24 horas.
🔵 CONTROL DE SEGURIDAD
Los métodos para hacer pagos seguros son los más reconocidos y que cumplen con las normativas PSD2. Adicionalmente, debes suministrar antes retirar el DNI o NIE en mejores casino online. Asimismo, si eliges tarjeta bancaria copia de ambas caras y con transferencia bancaria copia del comprobante con los 20 números que corresponden a la cuenta. Con monederos electrónicos la captura del identificador de tu cuenta.

JUEGOS DISPONIBLES EN LOS MEJORES CASINOS ONLINE ESPAÑOL
♥️ SLOTS ONLINE ESPAÑA
¿QUÉ SON LAS TRAGAPERRAS?
Son juegos en mejores casas de slots online mas populares diseñados sobre una temática en específico. Además, diariamente los desarrolladores les incorporan elementos extra para elevar la emoción y ganancias; como multiplicadores, comodines, scatters, megaways, carretes en cascada, jackpot slots etc.
¿CÓMO JUGAR A LAS SLOTS ONLINE ESPAÑA?
Elige el título que prefieras y revisa la tabla con los pagos. Luego selecciona tu apuesta, líneas de pago y seguidamente pulsa el botón girar. Si aciertas verás las ganancias obtenidas.
¿POR QUÉ JUGAR A LAS TRAGAPERRAS?
Sin lugar a dudas, las tragamonedas ofrecidas en los mejores casinos de España online son innovadoras y divertidas. Asimismo, incluyen elementos que aumentarán tus ganancias como las rondas con bonos.
♥️ ROULETTE
¿QUÉ ES LA RULETA?
Es un juego retador, ya que tienes que pronosticar el número donde parará la bola cuando se detenga la rueda. Además, existen 3 variantes de ruleta en mejores casinos conocidas como la europea, francesa y americana.
¿CÓMO SE JUEGA A LA RULETA?
Solo debes ingresar al juego con las reglas de la variante que te guste. Toma en consideración las reglas y el RTP de la variante que selecciones. Luego coloca tu apuesta interna o externa, si aciertas tu pronóstico cobrarás tus ganancias de inmediato.
¿POR QUÉ JUGAR A LA RULETA EN CASINO ONLINE?
Definitivamente porque es un juego popular, con reglas fáciles y ritmo rápido. Además, los casinos online Espana ofrecen variantes realmente desafiantes, con múltiples ruedas, dos bolas, doble cero, etc., que aumentarán tu adrenalina al máximo nivel.
♥️ BLACKJACK
¿QUÉ ES EL BLACKJACK?
También conocido como 21 es un entretenimiento que data del siglo XVIII. Donde se combina estrategia, elegancia, múltiples variantes y los RTP más elevados en la industria del juego online.
¿CÓMO SE JUEGA AL BLACKJACK EN MEJORES ONLINE CASINOS?
Escoge el blackjack online que prefieras e ingresa a la mesa y coloca tu apuesta. Espera que el dealer reparta las cartas, tus naipes tendrán que alcanzar un valor de 21. Dependiendo del total tendrás que elegir entre pedir más cartas, doblar o plantarte.
¿POR QUÉ JUGAR AL BLACKJACK?
Es fácil para aprender y el resultado no solo depende del azar, también influye la estrategia. Además, posee muchas variantes para escoger y tiene un RTP alto donde la ventaja del casinos online no supera el 2%.
♥️ JUEGOS EN VIVO
Las mesas con crupier en vivo tienen un ritmo más dinámico. Asimismo, los límites para apostar son mucho más elevados en los juegos live en casino online españa. Adicionalmente, existen más emoción y realismo en los casinos en vivo, porque eres atendido por crupieres reales.
Ahora bien, luego de conocer las diferencias entre los juegos online y en vivo. Querrás saber cuáles entretenimientos en vivo deberías probar. Los más populares en mejores casinos online son el blackjack en vivo, baccarat, ruleta live, póker en vivo, dados, sic bo y rueda de la fortuna.
♥️ RASCA Y GANA
Muchas personas son fanáticas del juego rasca y gana, porque reparten premios en efectivo a los jugadores de mejores casinos online España. Solo tienes que escoger el título, luego raspar los campos y, si coinciden los símbolos obtendrás tu recompensa. Como puedes ver es un juego simple, intrigante y muy emocionante.
♥️ BINGO
Entre los juegos sociales el bingo es el mejor. Actualmente puedes jugarlo en total comodidad online ingresando a una sala, donde vía chat puedes comunicarte con otros jugadores. También, elegir la variante según la cantidad de bolas, comprar tus cartones, activar el auto marcado y esperar conseguir el patrón ganador.








RTP MEDIO DE LOS JUEGOS DE CASINO
| Juegos | RTP |
| Póker | 99%- 100% |
| Ruleta | 97,30% |
| Blackjack | 99% |
| Baccarat | 99% |
| Tragamonedas | 98% |
EL TORNEO EN CASINOS RECOMENDADOS
Son eventos muy populares en un mejores casino online españoles, donde sus jugadores pagan una entrada y compiten por demostrar quién es el mejor. Es preciso señalar que, los juegos donde más torneos organizan figuran las tragamonedas, ruleta, póker y blackjack. Cabe destacar que, los torneos en línea más conocidos en España son:
- Carrera semanal de tragamonedas organizado por el casinos en espana.
- Slot Races impulsado por 888.
- Torneo de póker Gran Domingo ofrecido por 888.
- Torneo del juego blackjack organizado por Sportium.
SLOTS ONLINE ESPAÑA





TOP SOFTWARE DE JUEGOS DE MEJOR CASINO ONLINE
| Desarrolladores de software | Juegos |
| Microgaming | Tragamonedas, ruletas, blackjack, baccarat, póker, bingo, rasca y gana |
| Netent | Tragamonedas, ruletas, blackjack, baccarat, póker, bingo |
| Evolution Gaming | Ruleta, blackjack, baccarat, póker, Monopoly |
| Pragmatic Play | Tragamonedas, ruletas, blackjack, baccarat, póker |
| Yggdrassil | Online slots, ruletas |
| MGA | Tragamonedas, Blackjack, ruleta y catarata |
| Playtech | Tragamonedas, ruletas, blackjack, baccarat, póker, bingo. |
| PlayN’Go | Tragamonedas, ruleta, blackjack, póker, vídeo bingo |
| IGT | Slots, Lotería |
| Betsoft | Tragamonedas, ruleta, blackjack, craps y video póker. |
| iSoftbet | Tragamonedas, baccarat, ruleta, blackjack, póker, Punto Banco |
| Quickspin | Tragamonedas |
| 1x2Gaming | Tragamonedas, baccarat, ruleta, blackjack, Sic Bo. |
| Novomatic | Bingo, mejores slots online, ruleta |
| Red Tiger | Slots online |
CASINOS FÍSICOS VS CASINO ONLINE RECOMENDADO
| Casinos físicos | Casinos online |
|
|
LOS MEJORES CASINOS FÍSICOS MÁS POPULARES EN ESPAÑA
🌇 BARCELONA – Se encuentra en Barcelona, España, y es uno entre los pocos que ofrecen sede física y casino online. Incluye todo tipo de apuestas, destacando por una cantidad mayor a 800 máquinas tragaperras, un gran atractivo al jugar.
🌇 GRAN VÍA – Está entre los lugares más grandes e importantes en Madrid y toda España. Es un gran punto de concentración en el que se han realizado varios torneos de póker entre los más populares y concurridos.
🌇 GRAN CASINO COSTA BRAVA – Se encuentra en Lloret de Mar y posee uno de los diseños más asombrosos a nivel mundial; reina la modernidad, así como también múltiples juegos clásicos (como las máquinas tragaperras) y diversas mesas para jugar cartas. Usuarios resaltan especialmente la atención al apostador.
🌇 MARBELLA – En Marbella tiene una amplia diversidad en tragaperras y juegos de mesa, especialmente el póquer, con varios torneos internacionales organizados cada año.

🔴 EXISTEN NUEVAS REGLAS PARA RECIBIR BONOS EN MEJORES CASINOS ONLINE EN ESPAÑA 🔴
Sí, efectivamente existen bonos y promociones disponibles. Los casinos españoles con licencia otorgada por la DGOJ aún tienen promociones disponibles que ofrecer. No obstante, para cumplir con las nuevas leyes, las distintas bonificaciones solamente estarán dirigidas a clientes que tengan más de 30 días de haberse registrado. Esto significa que, no habrá bonos en el primer día de registro en casino online. Además, las ofertas promocionales serán personalizadas y los jugadores recibirán notificaciones cuando estén disponibles, para que el cliente decida si las acepta.
✨ CÓMO ELEGIR LOS BONOS EN UN MEJORES CASINO ONLINE ESPAÑOL ✨
Cuando ingresas a un casino en linea, es recomendable echarle un vistazo a las promociones que incluyen bonificaciones para jugadores registrados. Estos bonos incluyen términos y condiciones que deben ser leídos y aceptados si son convenientes para tu estilo de apuesta y sí calificas para reclamar alguno. A continuación, conoce cuáles son los bonos más populares.
- Giros gratis
Los bonos giros gratis te permiten hacer apuestas reales y ganar premios en diversos juegos, como slot online españa o juegos de mesa como la ruleta, el blackjack, póker, entre otros. Normalmente, tienen un número limitado para girar gratis y una ganancia máxima. Además, están las fichas para giros gratis, especialmente para casino en vivo, sin embargo, son menos frecuentes.
- Bonos de bienvenida
Los bonos de bienvenida, como su nombre lo indica, están pensados para jugadores nuevos que ser registran y hacen su primer depósito. Por lo regular, el depósito se ve duplicado por este bono, permitiéndole al nuevo jugador explorar más juegos sin gastar todos sus propios fondos.
- Bonos de depósito
Los bonos de depósito suelen ser un incremento del 50% o menos de tus fondos. Suelen darse en cualquier fecha del año o momentos especiales. Con este aumento, el jugador podrá jugar, por lo regular, en cualquier juego que desee.
- Bonos sin depósito
El bono sin depósito está pensado para los nuevos jugadores, por lo que está dentro de la categoría bono bienvenida. Por lo general, el casino suele dar dinero en efectivo para que el jugador pueda disponer del bankroll y elegir cualquier juego. Otras veces se dan giros gratis en lugar del dinero.
- Bonos diarios
Los bonos diarios son cualquier promoción que hace el casino a sus jugadores registrados. Estos bonos pueden ser un aumento en el depósito, una devolución del 10% o más en apuestas perdidas, entre otras.
- Bonos Drops and Win
Son torneos especiales organizados por los casinos y proveedores para jugar en títulos especiales, por ejemplo en tragaperras, y donde ser reparte bolsas de premios en efectivo a los los jugadores que se clasifican entre los mejores.




¿QUÉ HACER EN CASO DE TENER UN PROBLEMA EN ALGÚN MEJOR CASINO?
Si te haces cliente en casinos online españoles, es probable que en algún momento tengas dudas. A continuación, presentamos los canales para comunicarte con el operador.
| Atención al cliente | Tiempo respuesta |
| Chat en vivo | Instantánea |
| Correo electrónico | Hasta 24 horas después |
| Teléfono | Instantáneo |
❇️ ENVÍA UN CORREO ELECTRÓNICO
Si te gusta escribir y tienes mucho que preguntar será conveniente para ti utilizar este método para contactar el mejor casino online totalmente gratis. Ya que, podrás exponer los motivos con detalles, pero toma en cuenta que el lapso para recibir una respuesta es mínimo 24 horas.
❇️ CONTACTA POR TELÉFONO
El contacto telefónico es excelente si te gusta una atención más directa, rápida y personalizada. Incluso, algun mejores casino Espana online tienen un sistema donde pides que te llamen y te contactan en 10 minutos.
❇️ USA EL CHAT EN VIVO PARA COMUNICARTE
Es un canal cómodo, sin costo e inmediato. Solo pulsa clic en el ícono y puedes hacerle tus consultas a un operador entrenado para asesorarte. Recuerda verificar si el chat en casino online España trabaja en horario limitado.
❇️ CONSULTA LA SECCIÓN DE PREGUNTAS FRECUENTES
Es ideal cuando tienes dudas donde no se requiera la intervención de un asesor al usuario. Además, con los filtros se facilita la búsqueda de los temas que te interesa aclarar. Asimismo, solo tardarás unos minutos en aclarar tus interrogantes.
❇️ USA LAS REDES SOCIALES
Si tienes cuenta en las plataformas sociales, vale la pena seguir al casino donde eres cliente. Podrás enviarles mensajes privados para consultar ciertos aspectos y obtener respuestas en minutos.
❇️ LEE LAS EXPERIENCIAS DE OTROS USUARIOS EN LOS FOROS
Otros jugadores, podrían aclararte tus dudas mediante sus experiencias en los foros. Incluso, puedes formular una pregunta y cualquier usuario te la aclararía rápidamente.
📌 JUEGA DE FORMA RESPONSABLE EN CASINO EN LÍNEA ESPAÑA 📌
Cuando apuestes en mejor casino online debes jugar con responsabilidad. Recuerda que el juego es para divertirse, no para hacerse millonario. Asimismo, nunca inviertas todo tu dinero apostando, planifica un presupuesto y cumple primero con tus compromisos económicos. Adicionalmente, evita hacer apuestas estando ebrio o deprimido.
ORGANIZACIÓN QUE PUEDE AYUDARLE A JUGAR RESPONSABLEMENTE EN MEJORES CASINO ONLINE ESPANA
- JugarBIEN: Plataforma creada por la Dirección General de Ordenación del Juego que orienta a jugar con responsabilidad.
- APAL: Asociación que previene y trata las acciones conductuales como la ludopatía.
- FEJAR: Orienta sobre cómo prevenir la ludopatía por apuestas online.



🔎 PREGUNTAS FRECUENTES DE MEJORES CASINOS ONLINE ESPANA 🔎
- ¿CUÁL ES EL MEJOR CASINO ONLINE EN ESPAÑA PARA JUGADORES?
- Es muy difícil elegir un casino. Pero creemos que los jugadores deberían marcar 888, Gratogana, Codera, Casumo.
- ¿CÓMO GANAR DINERO CON LOS CASINOS ONLINE?
- Aprenda estrategias, haga un depósito pequeño primero para probar, lea los comentarios de los jugadores, vea blogueros de casino populares que explican cómo jugar juegos de casino.
- ¿QUÉ JUEGOS DE CASINO ONLINE SON MÁS POPULARES EN ESPAÑA?
- Definitivamente tragamonedas. Pero juegos como el póquer, la ruleta y las cartas de rascar también son muy populares.
- ¿LOS CASINOS EN LÍNEA TE REGLAN DINERO?
- No, pero pueden ofrecerle bonos por jugar tragamonedas en línea sin hacer un depósito.
- ¿SON LEGALES LOS CASINOS EN ESPAÑA?
- Sí, los paginas en línea en España que tienen licencias son absolutamente legales y confiables para los jugadores.
- ¿DÓNDE PUEDO ENCONTRAR LOS MEJORES CASINOS ONLINE EN ESPAÑA?
- En nuestro sitio Juego Siesta preparamos una lista de casinos en línea seguros y con licencia para jugadores españoles.
- ¿ES NECESARIO REGISTRARSE EN LOS CASINOS PARA OBTENER LAS BONIFICACIONES?
- Sí. Los bonos sin depósito y de bienvenida serán activados solo tras completar el registro en la plataforma. De lo contrario, no se podrá recibir ninguna bonificación.
- ¿SE PUEDE APOSTAR DESDE DISPOSITIVOS MÓVILES?
- Actualmente, la mayoría de los sitios opta por desarrollar su app móvil con juegos en lenguaje de programación HTML5 para ofrecer una excelente experiencia para los dispositivos móviles. Sin embargo, también se puede acceder directamente desde el navegador del dispositivo.
